What is a database?
In plain language:
A database is an organised collection of data.
Data in a database is organised into tables. Tables (or tabulated data) is sometimes referred to as schemas, datasets, entities or relations (these words do have different meanings in different contexts). Consider the following data flow diagram of a sports carnival information system. It might have its data organised into two tables - athlete and competition:
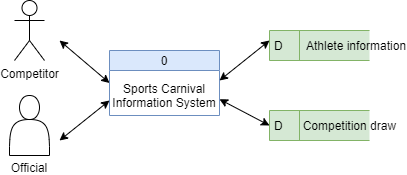
There are a few processes used when designing an efficient and error-free table structure, such as normalisation, enforcing constraints and partitioning, but they will come later on.
A table relation is a set of tuples.
"A table relation is a set of tuples" is just a fancy way of saying every record in a database must be unique - because sets are collections of unique elements, and tuples contain sequenced (meaning indexed), heterogeneous data (meaning different datatypes - integer, string etc). Although tuples are immutable (unchangeable), sets are not.
This is the big difference between a database and a spreadsheet - databases are built for managing much larger amounts of error-free data.
Each table can be broken down further into records (also known as rows, tuples, entries or results) and fields (also known as attributes, columns or column headings):
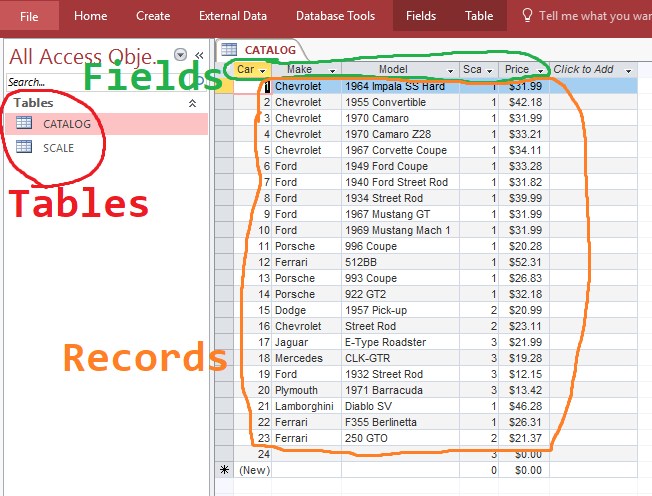
Questions
- In the classic cars database pictured above:
- Name the two tables in the database.
- How many fields are there in the CATALOG table?
- How many records are there in the CATALOG table?
- In the classic cars database pictured above there is an error with Car #24. There has been a record entered, but it has no make or model, and the price is the default $0. Assuming this database is used to display products online, why could an error in the data like this matter?